If you’ve tried building real-world features with AI, chances are that you’ve experienced reliability issues. It’s common knowledge that AI makes for great demos, but… questionable products. After getting uncannily correct answers at first, you get burned on reliability with some wild output and decide you can’t make anything useful out of that.
Well, I’m here to tell you that there’s hope. Even though AI agents are not reliable, it is possible to build reliable systems out of them.
These learnings come from a years-long process of creating a QA AI. While building, we found a process that worked pretty well for us and we’re sharing it here. As a summary, it consists of these high-level steps:
- Write simple prompts to solve your problem
- Use that experience to build an eval system to do prompt engineering and improve performance in a principled way
- Deploy your AI system with good observability, and use that signal to keep gathering examples and improving your evals
- Invest in Retrieval Augmented Generation (RAG)
- Fine-tune your model using the data you gathered from earlier steps
Having worked on this problem for a while, I think these are the best practices every team should adopt. But there’s an additional approach we came up with that gave us a breakthrough in reliability, and it might be a good fit for your product, too:
- Use complementary agents
The principle behind this step is simple: it’s possible to build systems of complementary agents that work much more reliably than a single agent. More on that later.
Before we jump in, a note on who this is for: you don’t need much AI experience to follow the process we lay out here. In fact, most of our team while building our QA agent didn’t have previous AI or ML experience. A solid software engineering background, however, is super helpful — a sentiment echoed by well-known people in the industry. Particularly, thinking deeply about how to test what you’re building and constantly finding ways to optimize your workflow are really important.
Start with simple prompts
The most obvious way to start using an LLM to solve a problem is simply asking it to do the thing in your own words. This approach often works well enough at the beginning to give you hope, but starts falling down as soon as you want any reliability. The answers you get might be mostly correct, but not good enough for production. And you’ll quickly notice scenarios where the answers are consistently wrong.
The best LLMs today are amazing generalists, but not very good specialists — and generally, you want specialists to solve your business problems. They need to have enough general knowledge to not be tedious, but at the same time they need to know how exactly to handle the specifics in the gray areas of your problem space.
Let’s take a trivial example: you want to get a list of ingredients needed to prepare different things to eat. You start with the first thing that comes to mind:
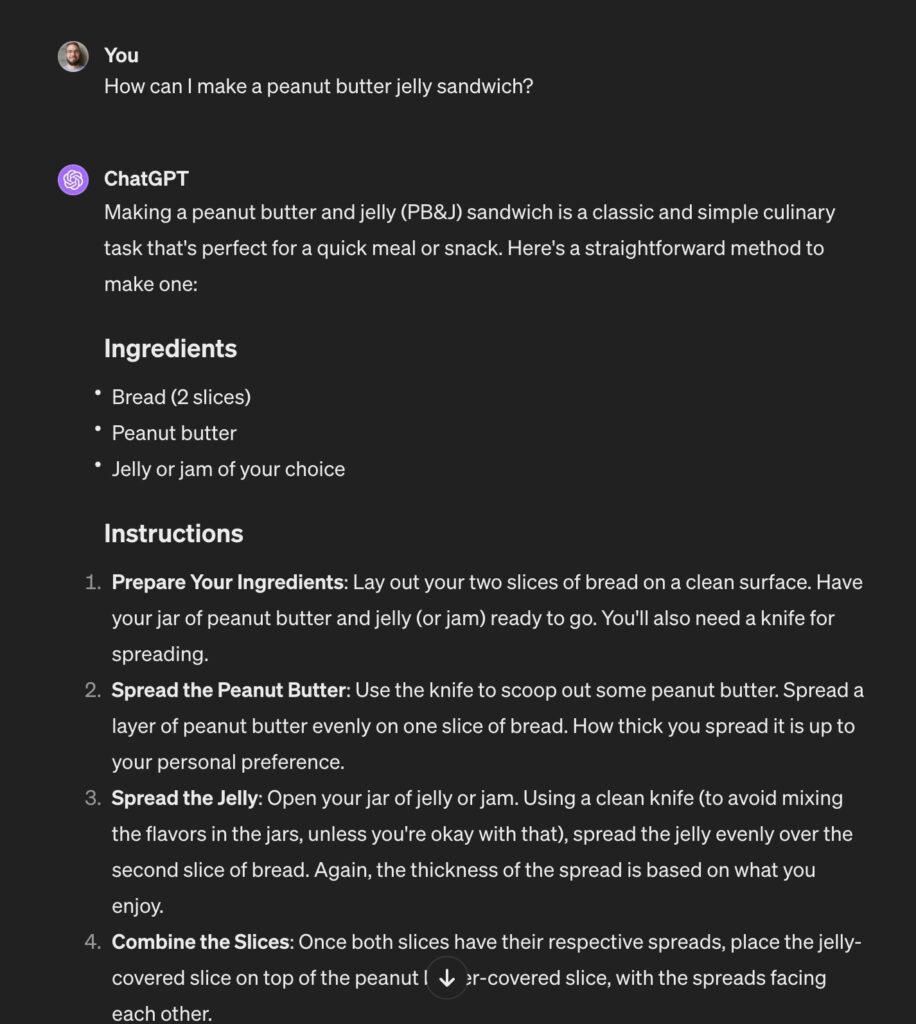
This is good — the list of ingredients is right there. But there’s also a bunch of other stuff that you don’t need. For example, you might use the same knife for both jars and not care for being lectured about knife hygiene. You can fiddle with the prompt pretty easily:
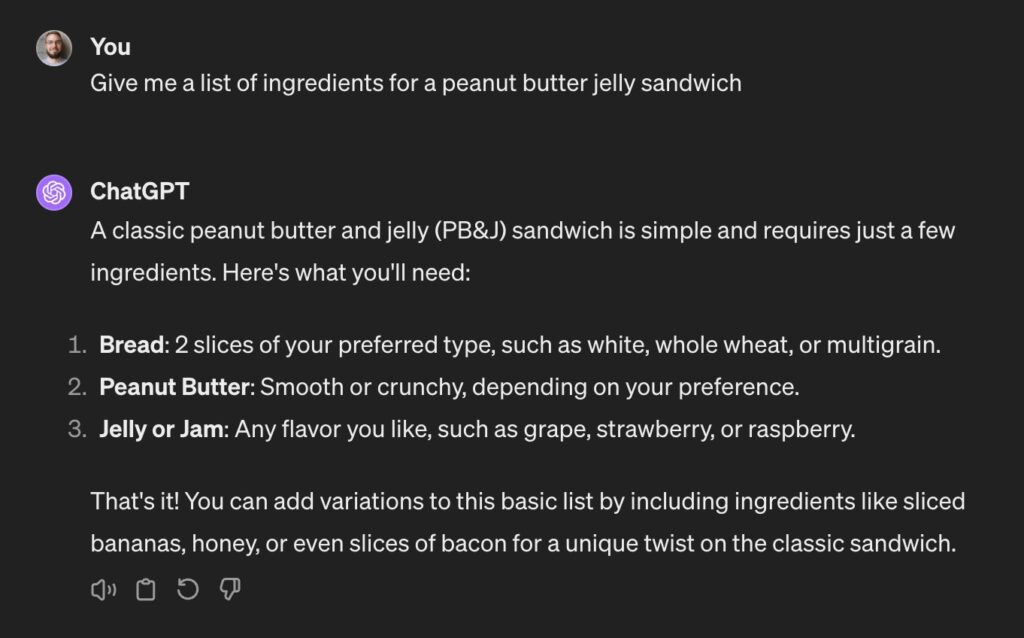
Better, but there’s still some unnecessary commentary there. Let’s have another shot:
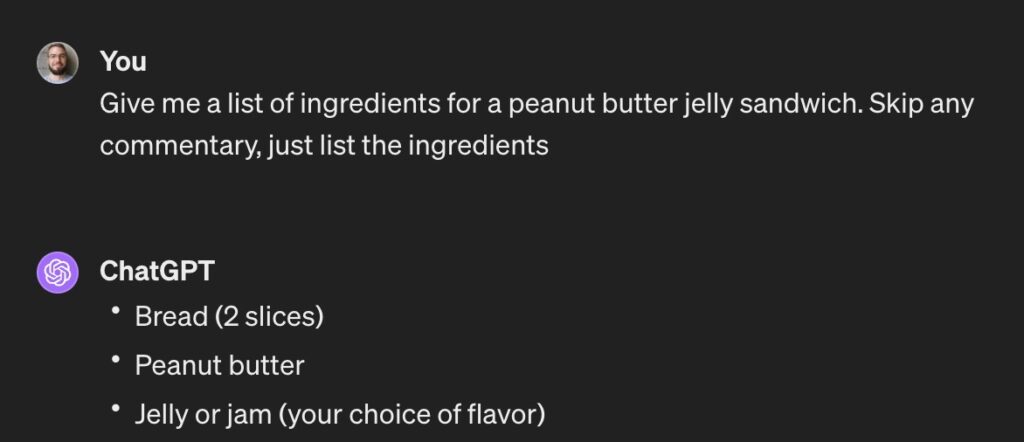
OK, I guess that’ll do. Now we just need to make it JSON so we can integrate it with the rest of our product. Also, just to be safe, let’s run it a few times to make sure it’s reliable:
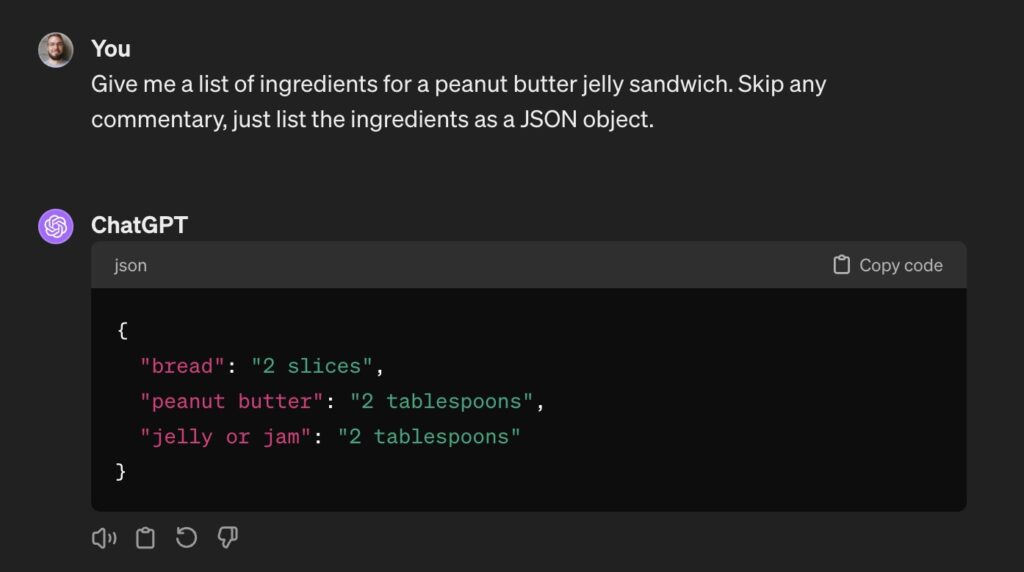
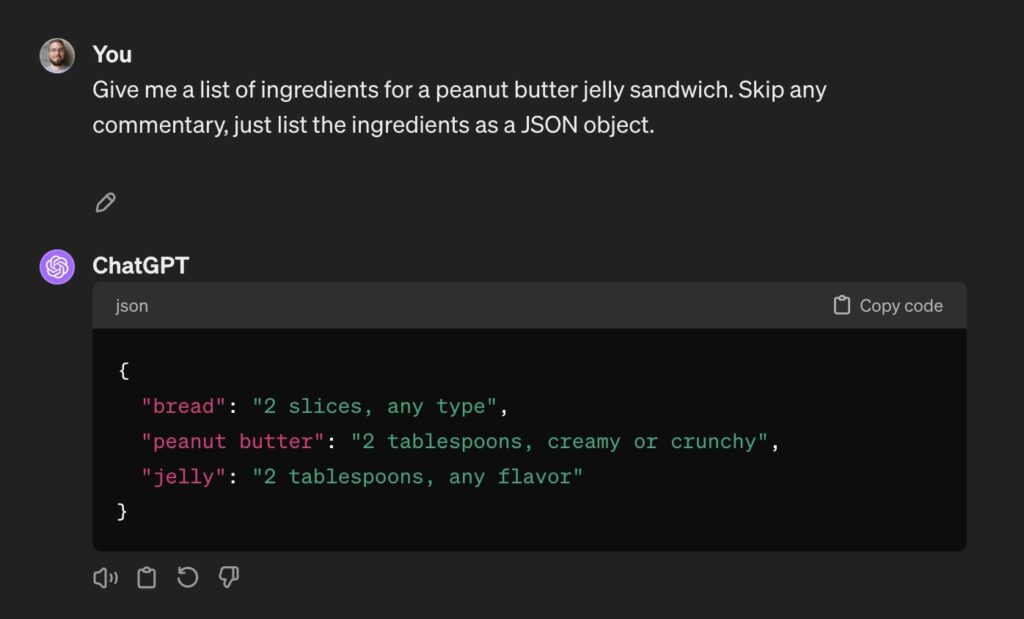
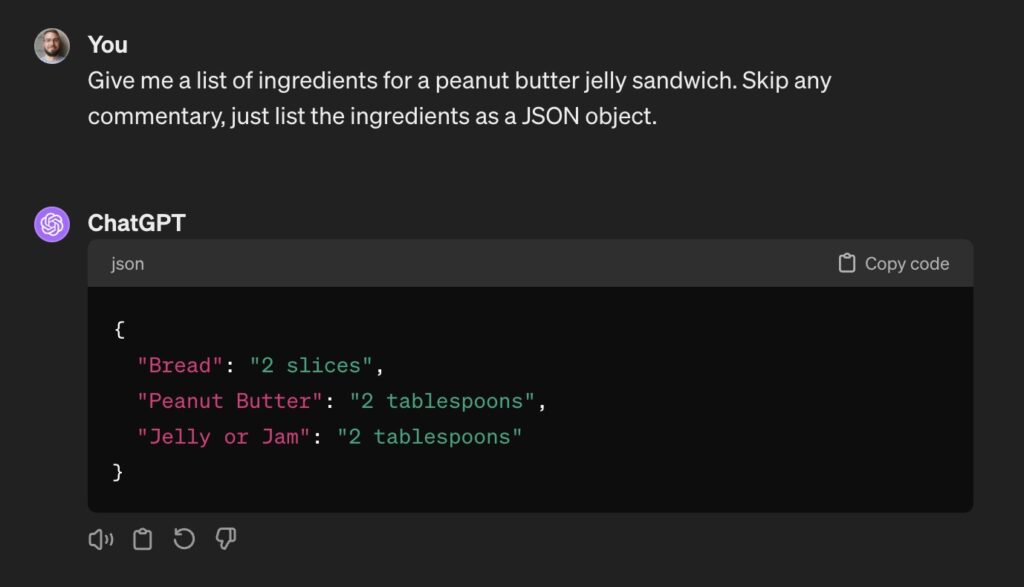
As you can see, we’re reliably getting JSON out, but it’s not consistent: the capitalization of the keys and what’s included in each value varies. These specific problems are easy to deal with and even this might be good enough for your use case, but we’re still far from the reliable and reproducible behavior we’re looking for.
Minimum necessary product integration
At this point, it’s time to integrate a minimal version of your “AI component” with your product, so the next step is to start using the API instead of the console. Grab your favorite LLM-provider client (or just use their API — there are some good reasons to stick with HTTP) and integrate it into your product in the most minimal way possible. The point is to start building out the infrastructure, knowing that the results won’t be great yet.
Some cheat codes at this point, based on my experience:
- If you use
mypy, you might be tempted to use strongly-typed inputs when interacting with the client (e.g., the OpenAI client), but my advice would be: don’t. While I like havingmypyaround, it’s much easier to work with plain dictionaries to build your messages and you’re not risking a lot of bugs. - In my experience, it’s a good idea to set
temperature=0.0in all your model calls if you care about reliability. You still won’t get perfect reproducibility, but it’s usually the best place to start your explorations. - If you’re thinking about using a wrapper like
instructorto get structured data out of the LLM: it’s really cool and makes some use-cases very smooth, but also makes your code a little less flexible. I’d usually start without it and then bring it in at a later point, once I’m confident in the shape of my data.
Use an eval system to do prompt engineering
The first thing you should try after the naive “ask a simple question” approach is prompt engineering. While the phrase is common, I don’t think many people have an accurate definition of what “prompt engineering” actually means, so let’s define it first.
When I say “prompt engineering,” I mean something like, “iterative improvement of a prompt based on measurable success criteria”, where “iterative” and “measurable success criteria” are the key phrases. (I like this post from last year as an early attempt to define this.) The key is to have some way of determining whether an answer you get from an LLM is correct and then measuring correctness across examples to give you a number you can compare over time.
Create an evaluation loop so you have a way of checking any change you make, and then make that loop as fast as it can be so you can iterate effectively. For an overview of how to think about your eval systems, see this excellent blog post.
Evaluating when there are multiple correct answers
This whole procedure rhymes with “testing” and “collecting a validation set,” except for any given question there might be multiple correct answers, so it’s not obvious how to do this. Here are some situations and how to deal with them:
- It’s possible to apply deterministic transformations on the output of the LLM before you compare it to the “known good” answer. An example might be the capitalization issue from earlier, or maybe you only ever want three first words as an output. Running these transformations will make it trivial to compare what you get with what you expect.
- You might be able to use some heuristics to validate your output. E.g., if you’re working on summarization, you might be able to say something like “to summarize this story accurately, the following words are absolutely necessary” and then get away with doing string matching on the response.
- Maybe you need the output in a certain format. E.g., you’re getting function calls or their arguments from an LLM or you’re expecting country codes or other well-defined outputs. In these cases, you can validate what you get against a known schema and retry in case of errors. In practice, you can use something like instructor — if you’re comfortable with the constraints it imposes, including around code flexibility — and then you’re left with straightforwardly comparing structured data.
- In a true Inception fashion, you might want to use a simpler, smaller, and cheaper LLM to evaluate the outputs of your big-LLM-using-component. Comparing two differently-written, but equivalent lists of ingredients is an easy task even for something like GPT 3.5 Turbo. Just keep in mind: even thought it’s pretty reliable, you’re now introducing some flakiness into your test suite. Trade-offs!
- To evaluate an answer, you might have to “execute” the entire set of instructions the agent gives you and check if you’ve reached the goal. This is more complex and time-consuming, but sometimes the only way. For example, we often ask an agent to achieve a goal inside a browser by outputting a series of instructions that might span multiple screens. The only way for us to check its answer is to execute the instructions inside Playwright and run some assertions on the final state.
Building your validation set
Once you have your evaluation loop nailed down, you can build a validation set of example inputs and the corresponding outputs you’d like the agent to produce.
As you evaluate different strategies and make changes to your prompts, it’s ideal if you have a single metric to compare over time. Something like “% prompts answered correctly” is the most obvious, but something like precision/recall might be more informative depending on your use case.
It’s also possible you won’t be able to use a single metric if you’re evaluating fuzzy properties of your answers, in which case you can at least look at what breaks after each change and make a judgment call.
Prompt engineering tricks
Now’s your chance to try all the prompt engineering tricks you’ve heard about. Let’s cover some of them!
First of all, provide all the context you’d need to give to an intelligent human operator who’s unfamiliar with the nuances and requirements of the task. This is a necessary (but not sufficient!) condition to making your system work. E.g., if you know you absolutely always want some salted butter under your peanut butter, you need to include that information in your prompt.
If you’re not getting the correct responses, ask the agent to think step-by-step before providing the actual answer. This can be a little tricky if you’re expecting structured data out — you’ll have to somehow give the agent a way to do some reasoning before it makes any consequential decisions and locks itself in.
E.g., if you use the tool-calling API, which is really nifty, you might be tempted to tell the agent to do some chain-of-thought reasoning by having a JSON schema similar to this:
[
{
"type": "function",
"function": {
"name": "scoop_out",
"description": "scoop something out",
"parameters": {
"type": "object",
"properties": {
"chain_of_thought": {
"type": "string",
"description": "the reasoning for this action"
},
"jar": {
"type": "string",
"description": "the jar to scoop out of"
},
"amount": {
"type": "integer",
"description": "how much to scoop out"
}
},
"required": ["chain_of_thought", "jar","amount"]
}
}
},
{
"type": "function",
"function": {
"name": "spread",
"description": "spread something on a piece of bread",
"parameters": {
"type": "object",
"properties": {
"chain_of_thought": {
"type": "string",
"description": "the reasoning for this action"
},
"substance": {
"type": "string",
"description": "what to spread"
}
},
"required": ["chain_of_thought", "substance"]
}
}
}
]Unfortunately, this will make the agent output the function name before it produces the chain-of-thought, locking it into the early decision and defeating the whole point. One way to get around this is to pass in the schema with the available functions, but ask the agent to output a JSON that wraps the function spec, similar to this:
You are an assistant helping prepare food. Given a dish name, respond with a JSON object of the following structure:
{{
"chain_of_thought": "Describe your reasoning for the next action",
"function_name": "scoop_out" | "spread",
"function_args": {{
< appropriate arguments for the function >
}}
}}This has fewer guarantees, but works well enough in practice with GPT 4 Turbo.
Generally, chain-of-thought has a speed/cost vs. accuracy trade-off, so pay attention to your latencies and token usage in addition to correctness.
Another popular trick is few-shot prompting. In many cases, you’ll get a noticeable bump in performance if you include a few examples of questions and their corresponding answers in your prompt, though this isn’t always feasible. E.g., your actual input might be so large that including more than a single “shot” in your prompt isn’t practical.
Finally, you can try offering the agent a bribe or telling it something bad will happen if it answers incorrectly. We didn’t find these tactics worked for us, but they might for you — they’re worth trying, assuming you trust your eval process.
Every trick from the ones listed above will change things: some things will hopefully get better, but it’s likely you’ll break something else at the same time. It’s really important you have a representative set of examples that you can work with, so commit to spending time on building it.
Improve with observability
At this point, you’ll likely have something that’s good enough to deploy as an alpha-quality product. Which you should absolutely do as soon as you can so you can get real user data and feedback.
It’s important you’re open about where your system is in terms of robustness, but it’s impossible to overstate the value of users telling you what they think. It’s tempting to get everything working correctly before opening up to users, but you’ll hit a point of diminishing returns without real user feedback. This is an absolutely necessary ingredient to making your system better over time — don’t skip it.
Before release, just make sure your observability practices are solid. From my perspective, this basically means logging all of your LLM input/output pairs so you can a) look at them and learn what your users need and b) label them manually to build up your eval set.
There a many options to go with here, from big monitoring providers you might already be using to open-source libraries that help you trace your LLM calls. Some, like openllmetry and openinference even use the OpenTelemetry under the hood, which seems like a great idea. I haven’t seen a tool focused on labeling the data you’ve gathered and turning it into a validation set, however, which is why we built our own solution: store some JSON files in S3 and have a web interface to look at and label them. It doesn’t have as many bells and whistles as off-the-shelf options, but it’s enough for what we need at the moment.
Invest in RAG
Once you’ve exhausted all your prompt-engineering tricks and you feel like you’re out of ideas and your performance is at a plateau, it might be time to invest in a RAG pipeline. Roughly, RAG is runtime prompt engineering where you build a system to dynamically add relevant things to your prompt before you ask the agent for an answer.
An example might be answering questions about very recent events. This isn’t something LLMs are good at, because they’re not usually retrained to include the latest news. However, it’s relatively straightforward to run a web search and include some of the most relevant news articles in your prompt before asking the LLM to give you the answer. If you have relevant data of your own you can leverage, it’s likely to give you another noticeable improvement.
Another example from our world: we’ve got an agent interacting with the UI of an application based on plain-English prompts. We also have more than ten years worth of data from our clients writing testing prompts in English and our crowd of human testers executing those instructions. We can use this data to tell the agent something like “it looks like most human testers executing similar tasks clicked on button X and then typed Y into field Z” to guide it.
Retrieval is great and very powerful, but it has real trade-offs, complexity being the main one. Again, there are many options: you can roll your own solution, use an external provider, or have some combination of the two (e.g., using OpenAI’s embeddings and storing the vectors in your Postgres instance).
A particular library that looked great (a little more on the do-it-yourself end of the spectrum) is RAGatouille, but I wasn’t able to make it work and gave up after a couple of hours. In the end, we used BigQuery to get data out, OpenAI for producing embeddings, and Pinecone for storage and nearest-neighbor search because that was the easiest way for us to deploy something without setting up a lot of new infrastructure. Pinecone makes it very easy to store and search through embeddings with their associated metadata to augment your prompts.
There’s more we can do here — we didn’t evaluate any alternative embedding engines, we only find top-3 related samples, and get limited data out of those samples currently. Looking at alternative embeddings, including more samples, and getting more details information about each sample is something we plan to look at in the future.
You can spend quite a while on this level of the ladder. There’s a lot of room for exploration. If you exhaust all the possibilities and ways of building your pipeline, still aren’t getting good enough results and can’t think any more sources of useful data, it’s time to consider fine-tuning.
Fine-tune your model
Now we’re getting to the edges of the known universe. If you’ve done everything above: created an eval system, shipped an AI product, observed it running in production, got real user data, and even have a useful RAG pipeline, then congratulations! You’re on the bleeding edge of applied AI.
Where to go from here is unclear. Fine-tuning a model based on the data you’ve gathered so far seems like the obvious choice. But beware — I’ve heard conflicting opinions in the industry about the merits of fine-tuning relative to the effort required.
It seems like it should work better, but there are unresolved practical matters: OpenAI only allows you to fine-tune older models, and Anthropic is kind of promising to make it available soon with a bunch of caveats.
Fine-tuning and hosting your own models is a whole different area of expertise. Which model do you choose as the base? How do you gather data for fine-tuning? How do you evaluate any improvements? And so on. In the case of self-hosted models, I’d caution against hoping to save money vs. hosted solutions — you’re very unlikely to have the expertise and the economies of scale to get there, even if you choose smaller models.
My advice would be to wait a few months for the dust to settle a bit before investing here, unless you’ve tried everything else already and still aren’t getting good-enough results. We haven’t had to do this so far because we still haven’t exhausted all the possibilities mentioned above, so we’re postponing the increase in complexity.
Use complementary agents
Finally, I want to share a trick that might be applicable to your problem, but is sort of independent of the whole process described above — you can apply it at any of the stages I’ve described.
It involves a bit of a computation vs. reliability trade-off: it turns out that in many situations it’s possible to throw more resources at a problem to get better results. The only question is: can you find a balance that’s both fast and cheap enough while being accurate enough?
You’ll often feel like you’re playing whack-a-mole when trying to fix specific problems with your LLM prompts. For instance, I often find there’s a tension between creating the correct high-level plan of execution and the ability to precisely execute it. This reminded me of the idea behind “pioneers, settlers, and city planners”: different people have different skills and approaches and thrive in different situations. It’s rare for a single person to both have a good grand vision and to be able to precisely manage the vision’s execution.
Of course, LLMs aren’t people, but some of their properties make the analogy work. While it’s difficult to prompt your way to an agent that always does the right thing, it’s much easier to plan what’s needed and create a team of specialists that complement each other.
I’ve seen a similar approach called an “ensemble of agents,” but I prefer “complementary agents” for this approach because it highlights that the agents are meaningfully different and support each other in ways that identical agents couldn’t.
For example, to achieve a non-obvious goal, it helps to create a high-level plan first, before jumping into the details. While creating high-level plans, it’s useful to have a very broad and low-resolution view of the world without getting bogged down by details. Once you have a plan, however, executing each subsequent step is much easier with a narrow, high-resolution view of the world. Specific details can make or break your work, and at the same time, seeing irrelevant information can confuse you. How do we square this circle?
One answer is creating teams of complementary agents to give each other feedback. LLMs are pretty good at correcting themselves if you tell them what they got wrong, and it’s not too difficult to create a “verifier” agent that checks specific aspects of a given response.
An example conversation between “high level planner” and “verifier” agents might look something like the following:
Planner
OK, we need to make a PB&J sandwich! To do that, we need to get some peanut
butter, some jelly and some bread, then take out a plate and a knife.
Verifier
Cool, that sounds good.
Planner
OK, now take the peanut butter and spread it on the bread.
Verifier
(noticing there's no slice of bread visible) Wait, I can't see the bread in
front of me, you can't spread anything on it because it's not there.
Planner
Ah, of course, we need to take the slice of bread out first and put it on a
plate.
Verifier
Yep, that seems reasonable, let's do it.
The two agents complement each other, and neither can work on its own. Nobody is perfect, but we can build a reliable system out of flawed pieces if we’re thoughtful about it.
How we’re using complementary agents
This is exactly what we did for our testing agents: there’s a planner and a verifier. The planner knows the overall goal and tries to achieve it. It’s creative and can usually find a way to get to the goal even if it isn’t immediately obvious. E.g., if you ask it to click on a product that’s not on the current page, it’ll often use the search functionality to look for the product. But sometimes the planner is too optimistic and wants to do things that seem like they should be possible, but in fact aren’t.
For example, it might want to click on a “Pay now” button on an e-commerce checkout page, because the button should be there, but it’s just below the fold and not currently visible. In such cases, the verifier (who doesn’t know the overall goal and is only looking at the immediate situation) can correct the planner and point out that the concrete task we’re trying to do right now isn’t possible.
Final notes
Putting all this together again, we now have a pretty clear process for building LLM-based products that deal with their inherent unreliability.
Making something usable in the real world still isn’t a well-explored area, and things are changing really quickly, so you can’t follow well-explored paths. It’s basically applied research, rather than pure engineering. Still, having a clear process to follow while you’re iterating will make your life easier and allow you to set the right expectations at the start.
The process I’ve described should follow a step-by-step increase in complexity, starting with naive prompting and finally doing RAG and possibly fine-tuning. At each step, evaluate whether the increased complexity is worth it — you might get good-enough results pretty early, depending on your use case. I bet getting through the first four steps will be enough to handle most of your problems.
Keep in mind that this is going to be a very iterative process — there’s no way to design and build AI systems in a single try. You won’t be able to predict what works and how your users will bend your tool, so you absolutely need their feedback. You’ll build the first, inadequate version, use it, notice flaws, improve it, release it more widely, etc. And if you’re successful and build something that gets used, your prize will be more iterations and improvements. Yay!
Also, don’t sweat having a single, optimizable success metric too much. It’s the ideal scenario, but it might take you a while to get to that point. Despite having a collection of tests and examples, we still rely “vibe checks” when evaluating whether a new prompt version is an improvement. Just counting passing examples might not be enough if some examples are more important than others.
Finally, try the “complementary agents” trick to work around weaknesses you notice. It’s often very difficult to make a single agent do the right thing reliably, but detecting the wrong thing so you can retry tends to be easier.
What’s next for us
There’s still a bunch of things that we’re planning to work on in the coming months, so our product won’t be static. I don’t expect, however, to deviate much from the process we described here. We’re continuously speaking with our customers and monitoring how our product is being used and finding edge cases to fix. We’re also certainly not at the global optimum when it comes to reliability, speed, and cost, so we’ll continue experimenting with alternative models, providers, and ways of work.
Specifically, I’m really intrigued by the latest Anthropic models (e.g., what can we usefully do with a small model like Haiku, which still has vision capabilities?) and I’m deeply intrigued by the ideas DSPy is promoting. I suspect there are some unrealized wins in the way we structure our prompts.